Hidden cartesian product

Introduction
There’s a project in my company that has a dedicated PostgreSQL virtual server with 12 cores and 32 GB RAM and it’s exclusively being used by one developer. He told me that he had an error with a query and checking the log file I could find: “ERROR: could not write block XXXX of temporary file: No space left”. But there were 27 GB free.
I asked him to run the query again to be able to see what was going on.
Analysis
The directory of PostgreSQL /data/pg_stat_tmp started growing until fill up the 27 GB! and PostgreSQL gave the out of space error again. Amazing.
The query had the typical INNER JOIN between a Products table and Orders table, with an aggregation on Orders table. I was really surprised for this behaviour. Here is the size (MB and rows) of the tables:
- public.Orders: 314 MB and 4.242.561 rows.
- public.Products: 189 MB and 1.108.514 rows.
The query plan was quite suspicious because I wasn’t expectiong a Nested Loop:
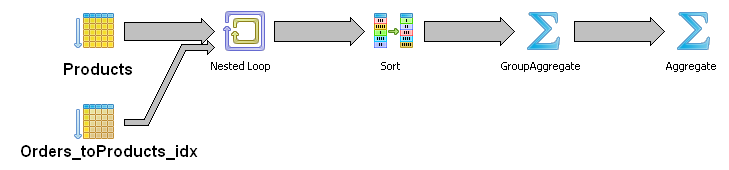
I changed the query doing the aggregation in a Common Table Expression and with the result I made the JOIN. It was just a fast test to see if I could find any clue about what was going on. It worked: 66 seconds. The query plan had the expected MERGE JOIN but it was doing a TABLE SCAN instead of using the indexes!
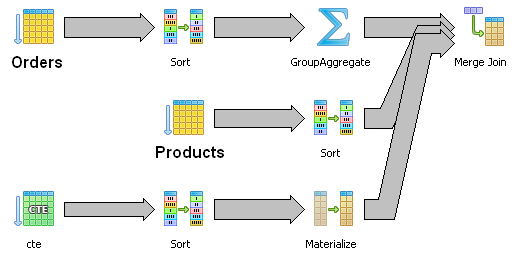
But 66 seconds was so much. So, diving into the problem I found that instead of NULL values, there were in both tables ‘1’ (number one). So we had a lot of ‘1’ in the joining columns! To be exact:
- public.Orders: 318.884 rows. 7,5% of total rows.
- public.Products: 184.324 rows. 16,6% of total rows.
So, we’ve: 318884 * 184324 = 58,777,974,416 rows!!
Yes, it’s like a cartasian product!
Solutions
Of course the obvious one in this case was to change the ones for nulls.
This is a development environtment and it’s far from critical. But in production, if users can make queries that are not controled by an application, we can set statement_timeout. It can be set globally in postgresql.conf or in connection basis.
